CDC Protect · Data Analyzation to Save Lives
As part of the CDC Protect team, I built robust web scrapers and data pipelines to analyze cannabinoid data, focusing on the visual similarity between edible cannabis packaging and children's candy packaging. The project highlighted risks of confusing designs and the need for stronger regulation.
Highlights
- Designed a recursive scraper (100+ layers) in Python using BeautifulSoup, Requests, and regex to gather structured/unstructured hospital website data.
- Developed URL management and retry/error-handling logic for resilience and efficiency.
- Automated distributed scraping with Slurm for HPC-scale data collection.
- Built dual scraping pipelines (Selenium for dynamic sites, BeautifulSoup for static sites).
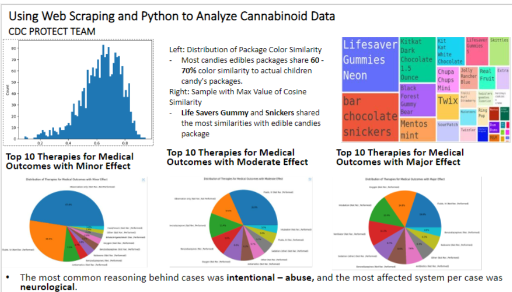
- Created CNNs to compare edible packaging with children’s candy, achieving +15% accuracy improvement.
- Performed statistical analysis on THC concentrations with Pandas and visualized insights via treemaps, bar charts, and histograms.
Stack
Python
BeautifulSoup
Selenium
Requests
Regex
Pandas
TensorFlow/CNN
Slurm
GCP
Data Visualization